This vignette provide guidance on when the bootstrap can be used for complex survey data and how to choose a bootstrap method and number of bootstrap replicates for a survey. It further demonstrates how to use functions from the “svrep” package to implement bootstrap methods and help decide the number of bootstrap replicates needed for your data.
The functions covered in this vignette include:
Functions for Creating Bootstrap Weights:
-
as_bootstrap_design(), which converts a survey design object to a replicate survey design object with bootstrap replicate weights.
Functions for Creating Generalized Survey Bootstrap Weights:
as_gen_boot_design(), which creates a replicate survey design using the generalized survey bootstrap method as described by Beaumont and Patak (2012).make_gen_boot_factors(), which creates a matrix of replicate weights using the generalized survey bootstrap method. This function will usually be used in conjunction with the functionsget_design_quad_form()ormake_quad_form_matrix(), which return the quadratic form matrix representation of common variance estimators.
Functions to Help Choose the Number of Bootstrap Replicates:
estimate_boot_sim_cv(), which estimates the simulation error of a bootstrap estimate.estimate_boot_reps_for_target_cv(), which estimates the number of bootstrap replicates needed to reduce a bootstrap’s simulation error to a target level.
Choosing a Bootstrap Method
Essentially every bootstrap method commonly used for surveys can be used for simple random sampling with replacement and can easily be applied to stratified sampling (simply repeat the method separately for each stratum). However, things become more complicated for other types of sampling and care is needed to use a bootstrap method appropriate to the survey design. For many common designs used in practice, it is possible (and easy!) to use one of the bootstrap methods described in the section of this vignette titled “Basic Bootstrap Methods.”
If the design isn’t appropriate for one of those basic bootstrap methods, then it may be possible to use the generalized survey bootstrap described in a later section of this vignette. The generalized survey bootstrap method can be used for especially complex designs, such as systematic sampling or two-phase sampling designs.
The interested reader is encouraged to read Mashreghi, Haziza, and Léger (2016) for an overview of bootstrap methods developed for survey samples.
Basic Bootstrap Methods
For most sample designs used in practice, there are three basic survey design features that must be considered when choosing a bootstrap method:
Whether there are multiple stages of sampling
Whether the design uses without-replacement sampling with large sampling fractions
Whether the design uses unequal-probability sampling (commonly referred to as “probability proportional to size (PPS)” sampling in statistics jargon)
The ‘svrep’ and ‘survey’ packages implement four basic bootstrap
methods, each of which can handle one or more of these survey design
features. Of the four methods, the Rao-Wu-Yue-Beaumont bootstrap method
(Beaumont and Émond 2022) is the only one
able to directly handle all three of these design features and is thus
the default method used in the function
as_bootstrap_design().1 The following table summarizes these four
basic bootstrap methods and their appropriateness for each of the common
design features described earlier.
| Method | Handles Multistage Samples? | Appropriate for Without-Replacement Sampling with Large Sample Fractions? | Unequal Probability Sampling (PPS)? |
|---|---|---|---|
| Rao-Wu-Yue-Beaumont | Yes | Yes | Yes |
| Rao-Wu | Only if first-stage sampling is without replacement or has a small sampling fraction | No | No |
| Preston | Yes | Yes | No |
| Canty-Davison | Only if first-stage sampling is without replacement or has a small sampling fraction | Yes | No |
| Antal-Tillé | Only if first-stage sampling is without replacement or has a small sampling fraction | Yes | Yes |
| Method | Strata IDs | Cluster IDs | Final Sampling Weights | Finite Population Corrections | Selection Probabilities by Stage |
|---|---|---|---|---|---|
| Rao-Wu-Yue-Beaumont | Yes | Yes | Yes | Yes, if sampling is without-replacement | If the design has unequal probability sampling (PPS) |
| Rao-Wu | Yes (first stage only) | Yes (first stage only) | Yes | No | No |
| Preston | Yes | Yes | Yes | Yes, if sampling is without replacement | No |
| Canty-Davison | Yes (first-stage only) | Yes (first stage only) | Yes | Yes (first stage only), if sampling is without replacement | No |
| Antal-Tillé | Yes (first-stage only) | Yes (first stage only) | Yes | Yes (first stage only), if sampling is without replacement | No |
Implementation
To implement these basic bootstrap methods, we can create a survey
design object with the svydesign() function from the survey
package, and then convert this object to a bootstrap replicate design
using as_bootstrap_design().
Below, we illustrate the use of bootstrap methods for examples with various kinds of sample designs. We use the Rao-Wu-Yue-Beaumont bootstrap method for all of these examples, as well as other bootstrap methods where applicable.
Example 1: Multistage Simple Random Sampling without Replacement (SRSWOR)
library(survey) # For complex survey analysis
library(svrep)
set.seed(2025)
# Load an example dataset from a multistage sample, with two stages of SRSWOR
data("mu284", package = 'survey')
multistage_srswor_design <- svydesign(
data = mu284,
ids = ~ id1 + id2,
fpc = ~ n1 + n2
)
# Create bootstrap replicate weights
bootstrap_rep_design <- as_bootstrap_design(
design = multistage_srswor_design,
type = "Rao-Wu-Yue-Beaumont",
replicates = 500
)
# Estimate variances with and without the use of bootstrap replicates
svytotal(x = ~ y1, design = multistage_srswor_design)
#> total SE
#> y1 15080 2274.3
svytotal(x = ~ y1, design = bootstrap_rep_design)
#> total SE
#> y1 15080 2341.8For multistage simple random sampling, Preston’s bootstrap method can also be used.
bootstrap_rep_design <- as_bootstrap_design(
design = multistage_srswor_design,
type = "Preston",
replicates = 500
)
svytotal(x = ~ y1, design = bootstrap_rep_design)
#> total SE
#> y1 15080 2297.1Example 2: Single-stage unequal probability sampling without replacement
# Load example dataset of U.S. counties and states with 2004 Presidential vote counts
data("election", package = 'survey')
pps_wor_design <- svydesign(
data = election_pps,
pps = HR(), # Method of estimating variance
fpc = ~ p, # Inclusion probabilities
ids = ~ 1 # Sampling unit IDs
)
# Create bootstrap replicate weights
boot_design <- as_bootstrap_design(
design = pps_wor_design,
type = "Rao-Wu-Yue-Beaumont",
replicates = 100
)
# Estimate variances with and without the use of bootstrap replicates
svytotal(x = ~ Bush + Kerry, design = pps_wor_design)
#> total SE
#> Bush 64518472 2472753
#> Kerry 51202102 2426842
svytotal(x = ~ Bush + Kerry, design = boot_design)
#> total SE
#> Bush 64518472 2456150
#> Kerry 51202102 2491278For single-stage unequal probability sampling, the Antal-Tillé bootstrap method can also be used.
antal_tille_boot_design <- as_bootstrap_design(
design = pps_wor_design,
type = "Antal-Tille",
replicates = 100
)
svytotal(x = ~ Bush + Kerry, design = antal_tille_boot_design)
#> total SE
#> Bush 64518472 2407341
#> Kerry 51202102 2412210Example 3: Multistage Sampling with Different Sampling Methods at Each Stage
For designs that use different sampling methods at different stages,
we can use the argument samp_method_by_stage to ensure that
the correct method is used to form the bootstrap weights. In general, if
a multistage design uses unequal probability sampling for only some
stages, then when creating the initial design object, the stage-specific
sampling probabilities should be supplied to the fpc
argument of the svydesign() function, and the user should
specify pps = "brewer".
# Declare a multistage design
# where first-stage probabilities are PPSWOR sampling
# and second-stage probabilities are based on SRSWOR
multistage_design <- svydesign(
data = library_multistage_sample,
ids = ~ PSU_ID + SSU_ID,
probs = ~ PSU_SAMPLING_PROB + SSU_SAMPLING_PROB,
pps = "brewer"
)
# Convert to a bootstrap replicate design
boot_design <- as_bootstrap_design(
design = multistage_design,
type = "Rao-Wu-Yue-Beaumont",
samp_method_by_stage = c("PPSWOR", "SRSWOR"),
replicates = 1000
)
# Compare variance estimates
svytotal(x = ~ TOTCIR, na.rm = TRUE, design = multistage_design)
#> total SE
#> TOTCIR 1634739229 250890030
svytotal(x = ~ TOTCIR, na.rm = TRUE, design = boot_design)
#> total SE
#> TOTCIR 1634739229 247959421Extracting Bootstrap Replicate Weights
All of the examples above used survey design objects from the ‘survey’ package. If we want to instead work with a dataframe containing the data and weights, we can convert the survey design object to a dataframe.
# Convert the survey design object to a data frame
output_data <- as_data_frame_with_weights(
design = boot_design,
full_wgt_name = "SAMP_WGT",
rep_wgt_prefix = "REP_WGT_"
)
# Inspect a few rows and columns
output_data[,c("LIBID", "SAMP_WGT", "REP_WGT_1", "REP_WGT_2", "REP_WGT_3")] |>
head(5)
#> LIBID SAMP_WGT REP_WGT_1 REP_WGT_2 REP_WGT_3
#> 1 AROO1-009 8.430076 12.2865125 11.0228829 10.7798395
#> 2 AR016 8.430076 20.8938676 18.7449983 6.3390194
#> 3 AE-PINAL 14.500000 28.4910686 28.4910686 28.4910686
#> 4 AE-AJ 14.500000 0.5089314 0.5089314 0.5089314
#> 5 M637 24.000000 47.4946802 47.4946802 47.4946802Instead of looking at the bootstrap replicate weights, we sometimes might want to look at the replicate factors. The replicate factors for a given bootstrap replicate indicate how many times each observation is resampled for that replicate.
We can extract replicate factors from a replicate survey design
object using the weights() function from the ‘survey’
package.
# Extract a matrix of replication factors
antal_tille_rep_factors <- antal_tille_boot_design |> weights(type = "replication")
# Inspect the replication factors
# for the first five observations and first five replicates
antal_tille_rep_factors[1:5,1:5]
#> [,1] [,2] [,3] [,4] [,5]
#> [1,] 0 1 1 1 1
#> [2,] 2 2 0 2 2
#> [3,] 0 0 1 0 2
#> [4,] 2 0 2 2 2
#> [5,] 2 2 2 0 0For complex survey bootstrap methods, the replication factors are often not integers but are instead real numbers. The Antal-Tillé bootstrap method is a notable exception where the replication factors are guaranteed to be integers. Below, we can see replication factors for the Rao-Wu-Yue-Beaumont bootstrap.
# Extract a matrix of replication factors
rep_factors <- boot_design |> weights(type = "replication")
# Inspect the replication factors
# for the first five observations and first five replicates
rep_factors[1:5,1:5]
#> [,1] [,2] [,3] [,4] [,5]
#> [1,] 1.45746158 1.30756620 1.27873568 1.18370614 1.39282150
#> [2,] 2.47849089 2.22358582 0.75195279 0.69607124 2.36856699
#> [3,] 1.96490128 1.96490128 1.96490128 1.96490128 0.03509872
#> [4,] 0.03509872 0.03509872 0.03509872 0.03509872 1.96490128
#> [5,] 1.97894501 1.97894501 1.97894501 1.97894501 0.02105499Generalized Survey Bootstrap
For sample designs with additional complex features beyond the three highlighted above, the generalized survey bootstrap method can be used. This is especially useful for systematic samples, two-phase samples, or complex designs where one wishes to use a general-purpose estimator such as the Horvitz-Thompson or Yates-Grundy estimator.
Statistical Background
The generalized survey bootstrap is based on a remarkable observation from Fay (1984), summarized nicely by Dippo, Fay, and Morganstein (1984):
…there is no variance estimator based on sums of squares and cross-products that cannot be represented by a resampling plan.
-- Dippo, Fay, and Morganstein (1984)
In other words, if a sample design has a textbook variance estimator for totals that can be represented as a quadratic form (i.e., sums of squares and cross-products), then we can make a replication estimator out of it. Fay developed a general methodology for producing replication estimators from a textbook estimator’s quadratic form, encompassing the jackknife, bootstrap, and balanced repeated replication as special cases. Within this framework, the “generalized survey bootstrap” developed by Bertail and Combris (1997) is one specific strategy for making bootstrap replication estimators out of textbook variance estimators. See Beaumont and Patak (2012) for a clear overview of the generalized survey bootstrap.
The starting point for implementing the generalized survey bootstrap method is to choose a textbook variance estimator appropriate to the sampling design which can be represented as a quadratic form. Luckily, there are many useful variance estimators which can be represented as quadratic forms. We highlight a few prominent examples below:
-
For stratified, multistage cluster samples:
- The usual multistage variance estimator used in the ‘survey’ package, based on adding variance contributions from each stage. The estimator can be used for any number of sampling stages.
-
Highly-general variance estimators which work for any ‘measurable’ survey design (i.e., designs where every pair of units in the population has a nonzero probability of appearing in the sample). This covers most designs used in practice, with the primary exceptions being “one-PSU-per-stratum” designs and systematic sampling designs.
The Horvitz-Thompson estimator
The Sen-Yates-Grundy estimator
-
For systematic samples:
- The SD1 and SD2 successive-differences estimators, which are the basis of the commonly-used “successive-differences replication” (SDR) estimator (see Ash (2014) for an overview of SDR).
-
For two-phase samples:
- The double-expansion variance estimator described in Section 9.3 of Särndal, Swensson, and Wretman (1992).
Once the textbook variance estimator has been selected and its quadratic form identified, the generalized survey bootstrap method consists of randomly generating each set of replicate weights from a multivariate distribution whose expectation is the -vector and whose variance-covariance matrix is the matrix of the quadratic form used for the textbook variance estimator. This ensures that, in expectation, the bootstrap variance estimator for a total equals the textbook variance estimator and thus inherits properties such as design-unbiasedness and design-consistency.
Details and Notation for the Generalized Survey Bootstrap Method
In this section, we describe the generalized survey bootstrap in greater detail, using the notation of Beaumont and Patak (2012).
Quadratic Forms
Let be the textbook variance estimator for an estimated population total of some variable . The base weight for case in our sample is , and we let denote the weighted value .
Suppose we can represent our textbook variance estimator as a quadratic form: , for some matrix . Our only constraint on is that, for our sample, it must be symmetric and positive semi-definite (in other words, it should never lead to a negative variance estimate, no matter what the value of is).
For example, the popular Horvitz-Thompson estimator based on first-order inclusion probabilities and second-order inclusion probabilities can be represented as a positive semi-definite matrix with entries along the main diagonal and entries everywhere else. An illustration for a sample with is shown below:
As another example, the successive-difference variance estimator for a systematic sample can be represented as a positive semi-definite matrix whose diagonal entries are all , whose superdiagonal and subdiagonal entries are all , and whose top right and bottom left entries are (Ash 2014). An illustration for a sample with is shown below:
To obtain a quadratic form matrix for a variance estimator, we can
use the function make_quad_form_matrix(), which takes as
inputs the name of a variance estimator and relevant survey design
information. For example, the following code produces the quadratic form
matrix of the “SD2” variance estimator we saw earlier.
make_quad_form_matrix(
variance_estimator = "SD2",
cluster_ids = c(1,2,3,4,5) |> data.frame(),
strata_ids = c(1,1,1,1,1) |> data.frame(),
sort_order = c(1,2,3,4,5)
)
#> 5 x 5 sparse Matrix of class "dsCMatrix"
#>
#> [1,] 1.0 -0.5 . . -0.5
#> [2,] -0.5 1.0 -0.5 . .
#> [3,] . -0.5 1.0 -0.5 .
#> [4,] . . -0.5 1.0 -0.5
#> [5,] -0.5 . . -0.5 1.0In the following example, we use this method to estimate the variance
for a stratified systematic sample of U.S. public libraries. First, we
create a quadratic form matrix to represent the SD2
successive-difference estimator. This can be done by using the
svydesign() function to describe the survey design and then
using get_design_quad_form() to obtain the quadratic form
for a specified variance estimator.
# Load an example dataset of a stratified systematic sample
data('library_stsys_sample', package = 'svrep')
# First, sort the rows in the order used in sampling
library_stsys_sample <- library_stsys_sample |>
dplyr::arrange(SAMPLING_SORT_ORDER)
# Create a survey design object
survey_design <- svydesign(
data = library_stsys_sample,
ids = ~ 1,
strata = ~ SAMPLING_STRATUM,
fpc = ~ STRATUM_POP_SIZE
)
# Obtain the quadratic form for the target estimator
sd2_quad_form <- get_design_quad_form(
design = survey_design,
variance_estimator = "SD2"
)
#> For `variance_estimator='SD2', assumes rows of data are sorted in the same order used in sampling.
class(sd2_quad_form)
#> [1] "dsCMatrix"
#> attr(,"package")
#> [1] "Matrix"
dim(sd2_quad_form)
#> [1] 219 219Next, we estimate the sampling variance of the estimated total for
the TOTCIR variable using the quadratic form.
# Obtain weighted values
wtd_y <- as.matrix(library_stsys_sample[['LIBRARIA']] /
library_stsys_sample[['SAMPLING_PROB']])
wtd_y[is.na(wtd_y)] <- 0
# Obtain point estimate for a population total
point_estimate <- sum(wtd_y)
# Obtain the variance estimate using the quadratic form
variance_estimate <- t(wtd_y) %*% sd2_quad_form %*% wtd_y
std_error <- sqrt(variance_estimate[1,1])
# Summarize results
sprintf("Estimate: %s", round(point_estimate))
#> [1] "Estimate: 65642"
sprintf("Standard Error: %s", round(std_error))
#> [1] "Standard Error: 13972"Forming Adjustment Factors
Our goal is to form sets of bootstrap weights, where the -th set of bootstrap weights is a vector of length denoted , whose -th value is denoted . This gives us replicate estimates of the population total, , for , from which we can easily calculate an estimate of the sampling variance.
We can write this bootstrap variance estimator as a quadratic form:
Note that if the vector of adjustment factors has expectation and variance-covariance matrix , then we have the bootstrap expectation . Since the bootstrap process takes the sample values as fixed, the bootstrap expectation of the variance estimator is . Thus, we can produce a bootstrap variance estimator with the same expectation as the textbook variance estimator simply by randomly generating from a distribution with the following two conditions:
Condition 1:
Condition 2:
The simplest, general way to generate the adjustment factors is to simulate from a multivariate normal distribution , which is the method used in this package. However, this method can lead to negative adjustment factors and hence negative bootstrap weights, which–while perfectly valid for variance estimation–may be undesirable from a practical point of view. Thus, in the following subsection, we describe one method for adjusting the replicate factors so that they are nonnegative and .
Adjusting Generalized Survey Bootstrap Replicates to Avoid Negative Weights
Let denote the matrix of bootstrap adjustment factors. To eliminate negative adjustment factors, Beaumont and Patak (2012) propose forming a rescaled matrix of nonnegative replicate factors by rescaling each adjustment factor as follows:
The value of can be set based on the realized adjustment factor matrix or by choosing prior to generating the adjustment factor matrix so that is likely to be large enough to prevent negative bootstrap weights.
If the adjustment factors are rescaled in this manner, it is important to adjust the scale factor used in estimating the variance with the bootstrap replicates, which becomes instead of .
When sharing a dataset that uses rescaled weights from a generalized survey bootstrap, the documentation for the dataset should instruct the user to use replication scale factor rather than when estimating sampling variances. This rescaling method does not affect variance estimates for linear statistics such as totals, but its affect on non-smooth statistics such as quantiles is unclear.
Implementation
There are two ways to implement the generalized survey bootstrap.
Option 1: Convert an existing design to a generalized bootstrap design
The simplest method is to convert an existing survey design object to a generalized bootstrap design.
With this approach, we create a survey design object using the
svydesign() function. This allows us to represent
information about stratification and clustering (potentially at multiple
stages), as well as information about finite population corrections.
# Load example data from stratified systematic sample
data('library_stsys_sample', package = 'svrep')
# First, ensure data are sorted in same order as was used in sampling
library_stsys_sample <- library_stsys_sample |>
sort_by(~ SAMPLING_SORT_ORDER)
# Create a survey design object
design_obj <- svydesign(
data = library_stsys_sample,
strata = ~ SAMPLING_STRATUM,
ids = ~ 1,
fpc = ~ STRATUM_POP_SIZE
)Next, we convert the survey design object to a replicate design using
the function as_gen_boot_design(). The function argument
variance_estimator allows us to specify the name of a
variance estimator to use as the basis for creating replicate
weights.
# Convert to generalized bootstrap replicate design
gen_boot_design_sd2 <- as_gen_boot_design(
design = design_obj,
variance_estimator = "SD2",
replicates = 2000
)
#> For `variance_estimator='SD2', assumes rows of data are sorted in the same order used in sampling.
# Estimate sampling variances
svymean(x = ~ TOTSTAFF, na.rm = TRUE, design = gen_boot_design_sd2)
#> mean SE
#> TOTSTAFF 19.756 4.2251For a PPS design that uses the Horvitz-Thompson or Yates-Grundy estimator, we can create a generalized bootstrap estimator with the same expectation. In the example below, we create a PPS design with the ‘survey’ package and convert it to a generalized bootstrap design.
# Load example data of a PPS survey of counties and states
data('election', package = 'survey')
# Create survey design object
pps_design_ht <- svydesign(
data = election_pps,
id = ~1,
fpc = ~p,
pps = ppsmat(election_jointprob),
variance = "HT"
)
# Convert to generalized bootstrap replicate design
gen_boot_design_ht <- pps_design_ht |>
as_gen_boot_design(variance_estimator = "Horvitz-Thompson",
replicates = 5000, tau = "auto")
# Compare sampling variances from bootstrap vs. Horvitz-Thompson estimator
svytotal(x = ~ Bush + Kerry, design = pps_design_ht)
svytotal(x = ~ Bush + Kerry, design = gen_boot_design_ht)We can also use the generalized bootstrap for designs that use multistage, stratified simple random sampling without replacement.
library(dplyr) # For data manipulation
# Create a multistage survey design
multistage_design <- svydesign(
data = library_multistage_sample |>
mutate(Weight = 1/SAMPLING_PROB),
ids = ~ PSU_ID + SSU_ID,
fpc = ~ PSU_POP_SIZE + SSU_POP_SIZE,
weights = ~ Weight
)
# Convert to a generalized bootstrap design
multistage_boot_design <- as_gen_boot_design(
design = multistage_design,
variance_estimator = "Stratified Multistage SRS"
)
# Compare variance estimates
svytotal(x = ~ TOTCIR, na.rm = TRUE, design = multistage_design)
#> total SE
#> TOTCIR 1634739229 251589313
svytotal(x = ~ TOTCIR, na.rm = TRUE, design = multistage_boot_design)
#> total SE
#> TOTCIR 1634739229 255663156Unless specified otherwise, as_gen_boot_design()
automatically selects a rescaling value
to use for eliminating negative adjustment factors. The
scale attribute of the resulting replicate survey design
object is thus set to equal
.
The specific value of
can be retrieved from the replicate design object, as follows.
# View overall scale factor
overall_scale_factor <- multistage_boot_design$scale
print(overall_scale_factor)
#> [1] 0.002
# Check that the scale factor was calculated correctly
tau <- multistage_boot_design$tau
print(tau)
#> [1] 1
B <- ncol(multistage_boot_design$repweights)
print(B)
#> [1] 500
print( (tau^2) / B )
#> [1] 0.002Option 2: Create the quadratic form matrix and then use it to create bootstrap weights
The generalized survey bootstrap can be implemented with a two-step process:
-
Step 1: Use
make_quad_form_matrix()to represent the variance estimator as a quadratic form’s matrix.
# Load an example dataset of a stratified systematic sample
data('library_stsys_sample', package = 'svrep')
# Represent the SD2 successive-difference estimator as a quadratic form,
# and obtain the matrix of that quadratic form
sd2_quad_form <- make_quad_form_matrix(
variance_estimator = 'SD2',
cluster_ids = library_stsys_sample |> select(FSCSKEY),
strata_ids = library_stsys_sample |> select(SAMPLING_STRATUM),
strata_pop_sizes = library_stsys_sample |> select(STRATUM_POP_SIZE),
sort_order = library_stsys_sample |> pull("SAMPLING_SORT_ORDER")
)-
Step 2: Use
make_gen_boot_factors()to generate replicate factors based on the target quadratic form. The function argumenttaucan be used to avoid negative adjustment factors using the previously-described method.
rep_adj_factors <- make_gen_boot_factors(
Sigma = sd2_quad_form,
num_replicates = 500,
tau = "auto"
)The actual value of tau used can be extracted from the
function’s output using the attr() function.
For convenience, the values to use for the scale and
rscales arguments of svrepdesign() are
included as attributes of the adjustment factors created by
make_gen_boot_factors().
# Retrieve value of 'scale'
rep_adj_factors |>
attr('scale')
#> [1] 0.04076
# Compare to manually-calculated value
(tau^2) / B
#> [1] 0.04076
# Retrieve value of 'rscales'
rep_adj_factors |>
attr('rscales') |>
head() # Only show first 5 values
#> [1] 1 1 1 1 1 1Using the adjustment factors thus created, we can create a replicate
survey design object by using the function svrepdesign(),
with arguments type = "other" and specifying the
scale argument to use the factor
.
gen_boot_design <- svrepdesign(
data = library_stsys_sample |>
mutate(SAMPLING_WEIGHT = 1/SAMPLING_PROB),
repweights = rep_adj_factors,
weights = ~ SAMPLING_WEIGHT,
combined.weights = FALSE,
type = "other",
scale = attr(rep_adj_factors, 'scale'),
rscales = attr(rep_adj_factors, 'rscales')
)This allows us to estimate sampling variances, even for quite complex sampling designs.
gen_boot_design |>
svymean(x = ~ TOTSTAFF,
na.rm = TRUE, deff = TRUE)
#> mean SE DEff
#> TOTSTAFF 19.7565 4.2014 0.9695Choosing the Number of Bootstrap Replicates
The bootstrap suffers from unavoidable “simulation error” (also referred to as “Monte Carlo” error) caused by using a finite number of replicates to simulate the ideal bootstrap estimate we would obtain if we used an infinite number of replicates. In general, the simulation error can be reduced by using a larger number of bootstrap replicates.
General Strategy
While there are many rule-of-thumb values for the number of replicates that should be used (some say 500, others say 1,000), it is advisable to instead use a principled strategy for choosing the number of replicates. One general strategy proposed by Beaumont and Patak (2012) is as follows:
Step 1: Determine the largest acceptable level of simulation error for key survey estimates. For example, one might determine that, on average, the bootstrap standard error estimate should be no more than different than the ideal bootstrap estimate.
Step 2: Estimate key statistics of interest using a large number of bootstrap replicates (such as 5,000) and save the estimates from each bootstrap replicate. This can be conveniently done using a function from the ‘survey’ package such as
svymean(..., return.replicates = TRUE)orwithReplicates(..., return.replicates = TRUE).Step 3: Estimate the minimum number of bootstrap replicates needed to reduce the level of simulation error to the target level. This can be done using the ‘svrep’ function
estimate_boot_reps_for_target_cv().
Measuring and Estimating Simulation Error
Simulation error can be measured as a “simulation coefficient of variation” (CV), which is the ratio of the standard error of a bootstrap estimator to the expectation of that bootstrap estimator, where the expectation and standard error are evaluated with respect to the bootstrapping process given the selected sample.
For a statistic , the simulation CV of the bootstrap variance estimator based on replicate estimates is defined as follows:
The simulation CV of a statistic, denoted , can be estimated for a given number of replicates by estimating using observed values and dividing this by . As a result, one can thereby estimate the number of bootstrap replicates needed to obtain a target simulation CV, which is a useful strategy for determining the number of bootstrap replicates to use for a survey.
With the ‘svrep’ package, it is possible to estimate the number of bootstrap replicates required to obtain a target simulation CV for a statistic.
library(survey)
data('api', package = 'survey')
# Declare a bootstrap survey design object ----
boot_design <- svydesign(
data = apistrat,
weights = ~pw,
id = ~1,
strata = ~stype,
fpc = ~fpc
) |>
svrep::as_bootstrap_design(replicates = 5000)
# Produce estimates of interest, and save the estimate from each replicate ----
estimated_means_and_proportions <- svymean(x = ~ api00 + api99 + stype,
design = boot_design,
return.replicates = TRUE)
# Estimate the number of replicates needed to obtain a target simulation CV ----
required_boot_reps <- estimate_boot_reps_for_target_cv(
svrepstat = estimated_means_and_proportions,
target_cv = c(0.01, 0.05, 0.10)
)
print(required_boot_reps)
#> TARGET_CV MAX_REPS api00 api99 stypeE stypeH stypeM
#> 1 0.01 15068 6650 6649 15068 15068 15068
#> 2 0.05 603 266 266 603 603 603
#> 3 0.10 151 67 67 151 151 151
plot(required_boot_reps)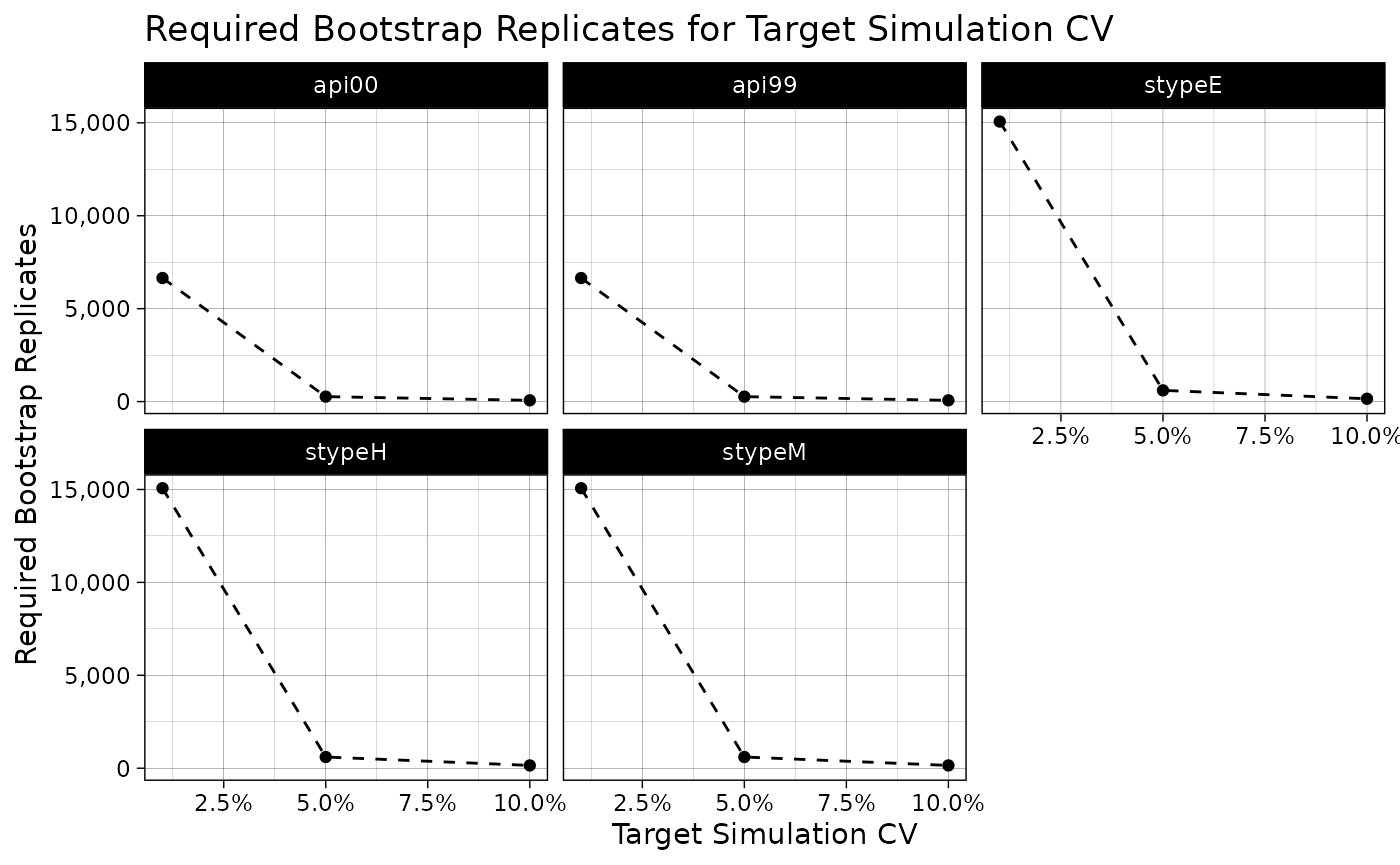
To estimate the simulation CV for the current number of replicates
used, it is possible to use the function
estimate_boot_sim_cv().
estimate_boot_sim_cv(estimated_means_and_proportions)
#> STATISTIC SIMULATION_CV N_REPLICATES
#> 1 api00 0.01153197 5000
#> 2 api99 0.01153134 5000
#> 3 stypeE 0.01735954 5000
#> 4 stypeH 0.01735949 5000
#> 5 stypeM 0.01735949 5000The Bootstrap vs. Other Replication Methods
Far better an approximate answer to the right question, which is often vague, than the exact answer to the wrong question, which can always be made precise.
-- John Tukey
Ok, but what if the approximate answer is, like, really approximate or requires a whole lot of computing?
-- Survey sampling statisticians
Survey bootstrap methods are directly applicable to a wider variety of sample designs than the jackknife or balanced repeated replication (BRR). Nonetheless, complex survey designs are often shoehorned into jackknife or BRR variance estimation by pretending that the actual survey design was something simpler. The BRR method, for instance, is only applicable to samples with two clusters sampled from each stratum, but statisticians frequently use it for designs with three or more sampled clusters by grouping the actual clusters into two pseudo-clusters. For designs with a large number of sampling units in a stratum, the exact jackknife (JK1 or JKn) requires a large number of replicates and so is often replaced by the “delete-a-group jackknife” (DAGJK) with clusters randomly grouped into larger pseudo-clusters.
Why do statisticians go to all this effort to shoehorn their variance estimation problem into jackknife or BRR methods when they could just use the bootstrap?
The simple answer is that bootstrap methods generally require many more replicates than other methods in order to obtain a stable variance estimate. And using a large number of replicates can be a problem if you have to do a large amount of computing or if your dataset is large and you’re concerned about storage costs. Statistical agencies are particularly sensitive to these concerns when they publish microdata, since agencies often serve a large number of end-users with varying computational resources.
So why use the bootstrap?
The bootstrap tends to works well for a larger class of statistics than the jackknife. For example, for estimating the sampling variance of an estimated median or other quantiles, the jackknife tends to perform poorly but bootstrap methods at least do an adequate job.
Bootstrap methods enable different options for forming confidence intervals. For all of the standard replication methods (BRR, Jackknife, etc.), confidence intervals are generally formed using a Wald interval ().2 But for certain bootstrap methods, it is possible to also form confidence intervals using other approaches, such as the bootstrap percentile method.
-
You can analyze your design rather than an approximation of your design, which can both reduce costs and better control errors. To use BRR for general survey designs, you have to approximate your actual survey design with a “two PSUs per stratum” design. This works surprisingly well in many cases, but it requires careful work on the part of a specially-trained statistician. For the jackknife with a large number of sampling units, you either end up with the same number of replicates as a bootstrap method or you have to randomly group your sampling units into a smaller number so you can use the DAGJK method to essentially approximate your actual survey design with a simpler one. Again, this takes careful work on the part of a specially-trained statistician.
By analyzing your design for what it is, you don’t have to pay a specially-trained statistician to meticulously approximate a design so that it can be shoehorned into a jackknife or BRR variance estimation problem, which is perhaps not the best use of a limited budget.
If the variance estimation is based on a bootstrap method tailored to the actual survey design, then the replication error in the variance estimates for key statistics is unbiased and can be quantified and controlled as a function of the number of replicates. In contrast, when variance estimation is based on approximating a design so that it can be shoehorned into a jackknife or BRR variance estimation problem, then the replication error in the variance estimates is more difficult to quantify and can consist of both noise and bias.
For most statisticians, it’s probably easier to learn. The bootstrap is the most well-known replication method among general statisticians, to the point that it’s often taught in first-year undergraduate statistics courses. So the basic idea is already familiar even to statisticians with only passing familiarity with complex survey sampling. BRR, in contrast, takes specialized training to learn and entails pre-requisite concepts such as Hadamard matrices, partial balancing, and so on. Outside of survey statistics, the jackknife tends to be much less used (and taught) compared to the bootstrap, due to its limitations with non-smooth statistics and the complexity required to make it work efficiently for large sample sizes.